6 min read
Feb 20, 2025

Overview
Are LLMs a total replacement for traditional OCR models? It's been an increasingly hot topic, especially with models like Gemini 2.0 becoming cost competitive with traditional OCR.
To answer this, we run a benchmark evaluating OCR accuracy between traditional OCR providers and Vision Language Models. This is run with a wide variety of real world documents. Including all the complex, messy, low quality scans you might expect to see in the wild.
The evaluation dataset and methodologies are entirely Open Source. You can run the benchmark yourself using the benchmark repository on Github. You can also view the raw data from the benchmark in the Hugging Face repository. The following results evaluate the top VLMs and OCR providers on 1,000 documents. We measure accuracy, cost, and latency for each provider.

OCR Providers
We evaluated two categories of OCR providers: Traditional OCR and Multimodal Language Models.
Traditional OCR providers (Azure, AWS Textract, Google Document AI, etc.) are evaluated using their default configurations, with the exception of Azure which supports a native Markdown output. Unstructured is evaluated using their “Advanced” strategy. Vision models (OpenAI, Gemini, Anthropic, etc.) are instructed to convert each document image into a Markdown format using HTML for tables (system prompt).
You can view a list of all providers and their configurations in the benchmark repository.
Methodology
The primary goal is to evaluate JSON extraction from documents. To evaluate this, the Omni benchmark runs Document ⇒ OCR ⇒ Extraction. Measuring how well a model can OCR a page, and return that content in a format that an LLM can parse.
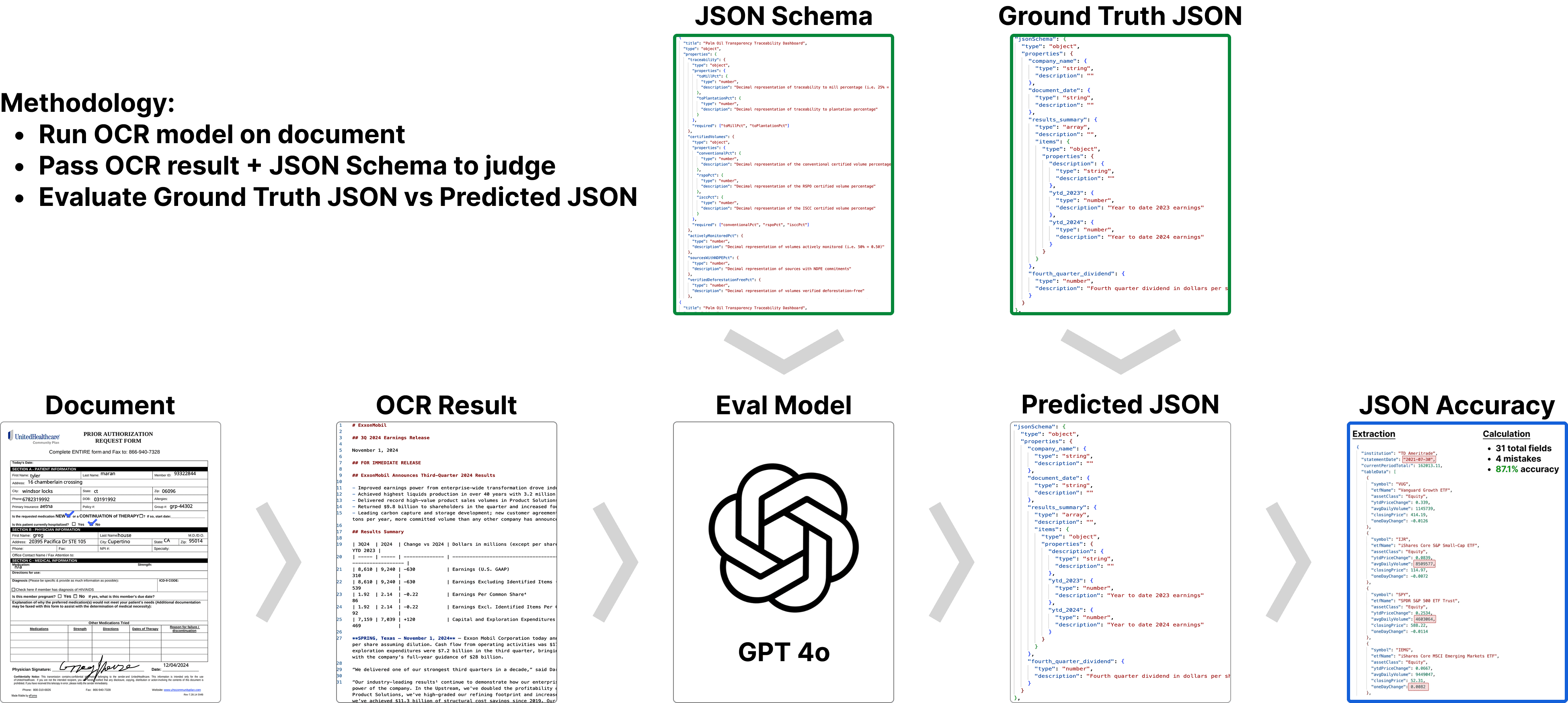
We are using GPT-4o as a judge. Passing in the OCR result + JSON schema using the structured extraction mode. We compare that to the ground truth JSON values to determine accuracy. Several LLMs with structured output were evaluated as judge (including GPT-4o, Claude 3.5 Sonnet, and Gemini 2.0 Flash). GPT 4o most consistently conformed to the JSON schema.
A ground truth accuracy is calculated by passing in the 100% correct text to GPT 4o along with the corresponding JSON Schema. There's always some variability with GPT even given the perfect text input, and we typically see 99% (+/-1%) accuracy on the ground truth.
Measuring Accuracy
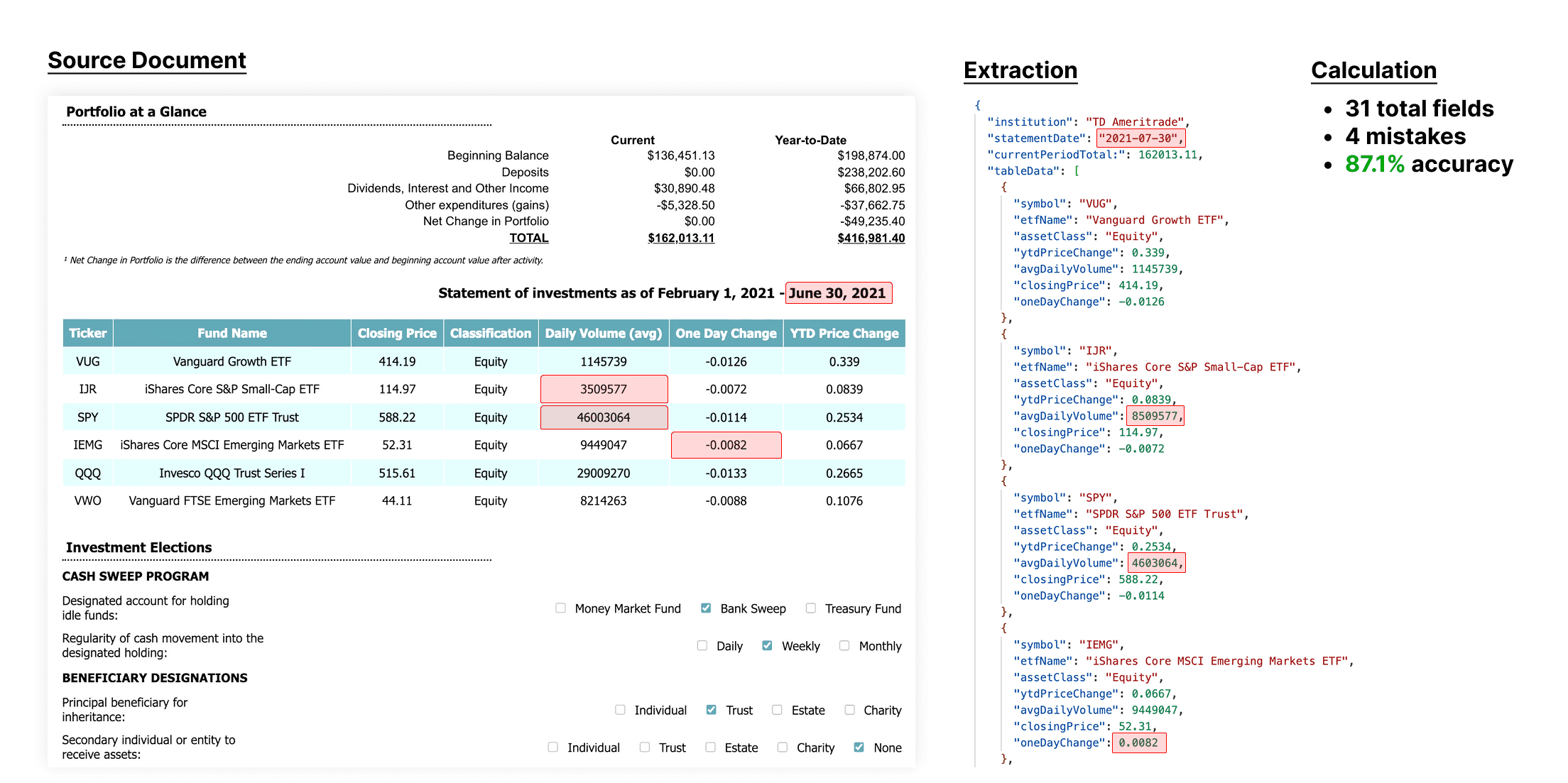
Accuracy is measured by comparing the JSON output from the OCR/Extraction to the ground truth JSON. We calculate the number of JSON differences divided by the total number fields in the ground truth JSON. We believe this calculation method lines up most closely with a real world expectation of accuracy.
Ex: if you are tasked with extracting 31 values from a document, and make 4 mistakes, that results in an 87% accuracy.
A note on array scoring. Order does not matter, but any change in a single value will be counted as two mistakes. In the example below, while prediction3 is off by only 1 character from the ground truth, this is scored as 1 addition + 1 subtraction ⇒ 50% accuracy.
The case against text-similarity
The majority of OCR benchmarks rely on some form of text similarity scoring. Often using Levenshtein or other Edit Distance based calculations. However this scoring method heavily penalizes accurate text that does not conform to the exact layout of the ground truth data.
Invoices are a pretty good example of how two blocks of text that are identical from a content perspective can score wildly different on a text similarity basis. Two column page headers can be rearranged in a variety of ways, but the content is still the same.
In the example below, an LLM could decode both blocks of text without any issue. All the information is 100% accurate, but slight rearrangements of the header text (address, phone number, etc.) result in a large difference on edit distance scoring.

Data Explorer
The data explorer allows you to view the raw data from the benchmark. The benchmark was run with 1,000 documents. The first 50 samples are displayed here. The full dataset is publicly available and can be viewed in the Benchmark Hugging Face repository.
Each document has 4 associated files::One image of the pageThe ground truth MarkdownThe ground truth JSONA corresponding JSON schema
The data used in the benchmark is a mixture of annotated and synthetic data. You can see this in the annotated/synthetic tag in the data explorer below. Documents are also grouped by a number of additional tags (e.g. tables, handwriting, photo, etc.)
A portion of the synthetic data has image post processing applied to it. This ranges from applying a grain/scanned effect, to printing and photographing the documents. To read more on the process of synthetic data generation, read about the Infinite PDF Generator.

Results
The following results evaluate the 10 most popular providers on 1,000 documents.
Overall VLMs performance matched or exceeded most traditional OCR providers. The most notable performance gains were in documents with charts/infograpics, handwriting, or complex input fieds (i.e. checkboxes, highlighted fields). VLMs are also more predictable on photos and low quality scans. They are generally more capable of "looking past the noise" of scan lines, creases, watermarks. Traditional models tend to outperform on high-density pages (textbooks, research papers) as well as common document formats like tax forms.
There is also a unique element of Content Policy that affects VLM performance. GPT 4o will refuse to process images of photo IDs or passports for example. Returning the classic "I'm sorry I can't do that" error. And its difficult to assess ahead of time which documents will be flagged.
JSON Accuracy
Accuracy is measured by comparing the JSON output from the OCR/Extraction to the ground truth JSON. We calculate the number of JSON differences divided by the total number fields in the ground truth JSON. We believe this calculation method lines up most closely with a real world expectation of accuracy.
Cost per 1,000 Pages
Cost is calculated on a per 1,000 pages basis. This is how most OCR providers prices. For VLMs this cost is based on the number of tokens processed. VLM cost is primarily driven by the output size (i.e. number of words on a page) as output tokens are more expensive than input tokens. The average VLM token usage was ~1,500 input tokens and ~1,000 output tokens.

Processing time per page
Latency is measured as the number of seconds it takes to OCR a single page. For VLMs this will vary based on the number of words on a page (i.e. the amount of time it takes for the LLM to type out the page). The average page required ~1,000 output tokens.

The future of this benchmark
The Omni OCR benchmark is an ongoing effort to provide an Open Source evaluation for OCR providers. We will continue to evaluate and update this benchmark as new providers are released and as the technology landscape evolves.
To maintain a fair benchmark, each new evaluation will be carried out with a novel document data set. This prevents providers from training specifically on the evaluation dataset. Given the high cost of producing quality labeled data, we plan to open source evaluation sets on a monthly cadence.
While we aim to create a balanced and representative dataset, we recognize that certain document types may not be adequately covered by this benchmark. If you would like run the evaluation framework on a proprietary set of documents, you can create custom benchmarks using our open source benchmark framework.
Additional publications: