8 min read
Dec 12, 2024

Infinite PDF Generator
Vision models (specifically VLMs) are the next and possibly final leap forward in OCR. Right out of the box models like 4o and Llama 3.3 do an incredible job on the documents where traditional OCR models fail. They do particularly well with tables, color coded charts, infographics, and handwriting.
They’re getting cheaper too. On average we see ~$4/1000 pages for GPT 4o vision. Which is getting pretty close to Azure OCR at $1/1000 pages.
So how to do we make VLM perform more reliably? We’ve learned a lot in the last several months deploying these models. Our findings boil down to:
VLMs are awesome, but not perfect.
Small volumes of fine tuning data makes a huge impact on accuracy. Especially on specific document formats.
High quality labeled data is particularly expensive to produce for this application. And we need lots of training data.
We should build an infinite PDF generator
For our purposes, training data means a straightforward input-output pair: image in, Markdown out. Now proper synthetic data is hard. But documents have enough built-in structure to set some natural limits on complexity. We’ve seen some terrible documents come through, but there is a logical upper bound to how much content can be crammed into a single page.
Why work on this:
We’re OmniAI, and recently launched Zerox, our open source document ⇒ markdown library. This takes any document format, turns it into a series of images, then uses a VLM to transcribe each image into Markdown.
You can test out the demo instance here: https://getomni.ai/ocr-demo
There and Back Again
JSON ⇒ Markdown ⇒ Image ⇒ LLM ⇒ Markdown ⇒ JSON
The general steps look like this:
Generate JSON based on a defined schema.
Convert that JSON into Markdown, following the same document schema. Supplement with some generated text.
Convert that JSON into HTML, again using the same schema.
Render the HTML as an image and save it.
Apply post-processing to clean up or degrade the image.
Which gives us three sets of training data:
Image ⇒ Markdown (OCR): Train the vision model to parse image data and produce clean Markdown. This is where 80% of extraction inaccuracies come from.
Markdown ⇒ JSON (Extraction): Improve extraction from clean markdown.
Image ⇒ JSON (Cut out the middle man): If we’re feeling ambitious, we can train the model to jump directly from a series of images to JSON, no Markdown required. Although it’s likely this approach will only work on smaller page documents.
Anatomy of a PDF
Our PDF generation starts by stacking page elements in a logical manner. Headings before text blocks, tables in appropriate sections, and so on. We then fill these elements with generated values that reflect the variety you’d find in real documents.

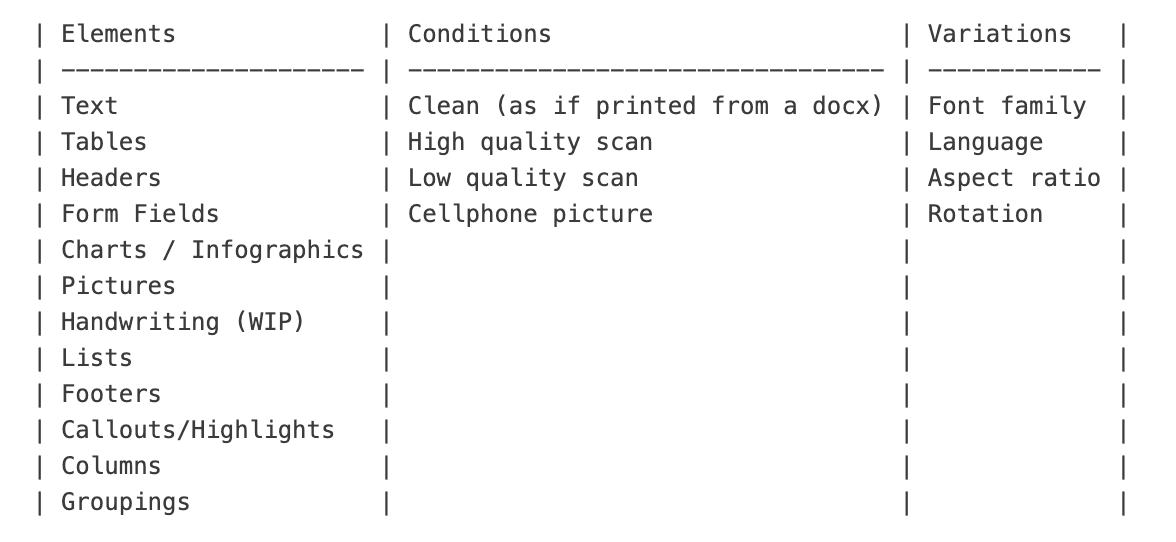
We break down pages into three high level concepts:
Elements: These are the building blocks of the page. Each element might be a heading, a paragraph, a list, or a table. We introduce variability here; lists can be ordered or unordered, arranged horizontally or with wrapping text, and styled differently.
Conditions: This refers to the overall “look and feel” of the page. Maybe the PDF is crisp and digital, or maybe it’s been printed, marked up, scanned, and then recompressed. The image degradation/noise/blur logic can be applied retroactively to any document.
Variations: Once we have a basic layout, we apply further tweaks. We might change the font family, alter the language, experiment with different page sizes, or even tilt and rotate the layout for added realism.
These are the variations we currently apply:
Generative vs. Templated
In our workflow, we generally work with two types of synthesized documents:
Purely generated documents: Starting with a general schema, we randomly produce entire documents. This includes content, layout, and various page conditions.
Templated documents: If we have a known document structure (like a standard tax form) we automate the form filling with representative data. We then apply the same page conditions as with fully generated documents.
The world exchanges billions of PDFs every day, but luckily a lot of them are the same templates. Synthetic generation for templated forms is a pretty well established practice, and how a lot of traditional single document OCR models are trained.
For templated documents, we have two main approaches:
Manual recreation in HTML: Rebuilding the document layout in HTML. This is a huge pain, and we haven’t really found a way around it. But it’s the most reliable way to get a “fillable” variant of any form. Fingers crossed someone like Figma creates a really good image⇒ styled HTML tool.
Using fillable forms: If the document has fillable form fields, we can simply map our JSON schema to these fields. This is much faster and requires less overhead.
The example below uses the fillable IRS Form. We start with a clean form, populate it with random data, and then pass it through the document degradation flow.

Maintaining consistent context
At the end of the day we want synthetic docs to be indistinguishable from real docs. For maximum realism, each document needs a coherent theme. An income statement shouldn’t suddenly morph into a refrigerator manual halfway through.
To avoid this, we generate content generation hierarchically, with that each section logically dependent on the one before it. This is a lot slower, since we’re processing page elements synchronously. but keeps the narrative consistent throughout the page.

This is where LLMs are a huge unlock for synthetic data. By itself, model outputs become pretty repetitive. For example, an LLM would typically do a terrible job at randomly generating an income statement (numbers and line items would be overly simplistic).

But LLMs are excellent at playing Mad LIb. And as long as we can feed in enough external randomization, the LLM can create plausible text. In this example, we’re giving it a company, the type of document it’s working on, the text element we want it to generate (i.e. footnote, definitions, etc.). Then we pass in the HTML table from the previous step as context.

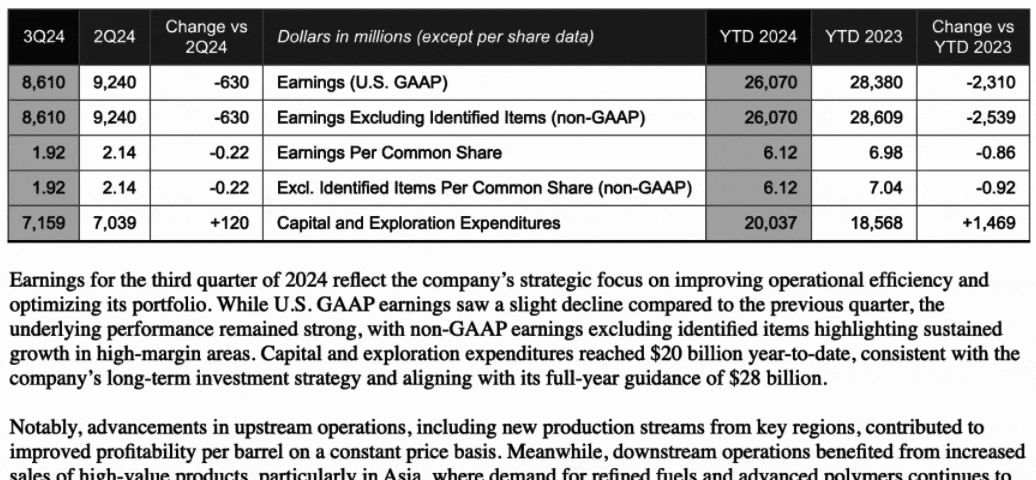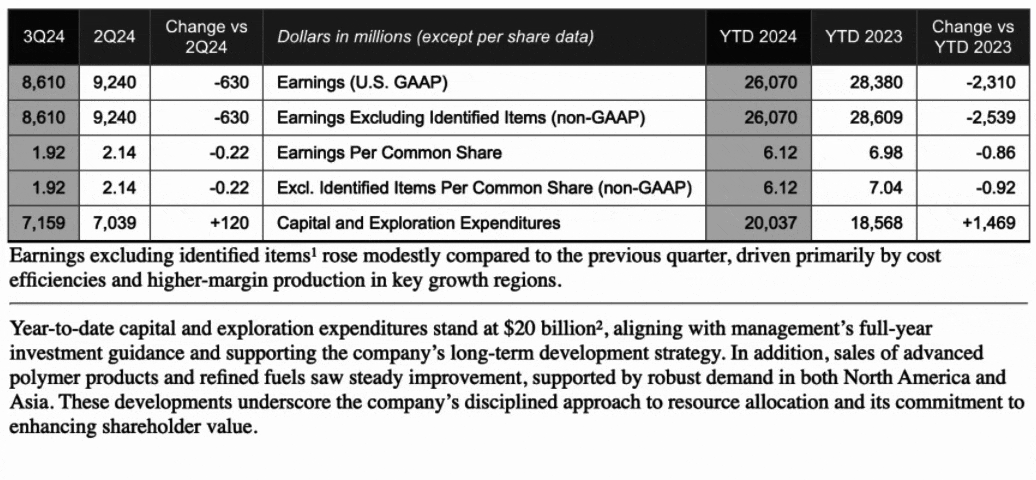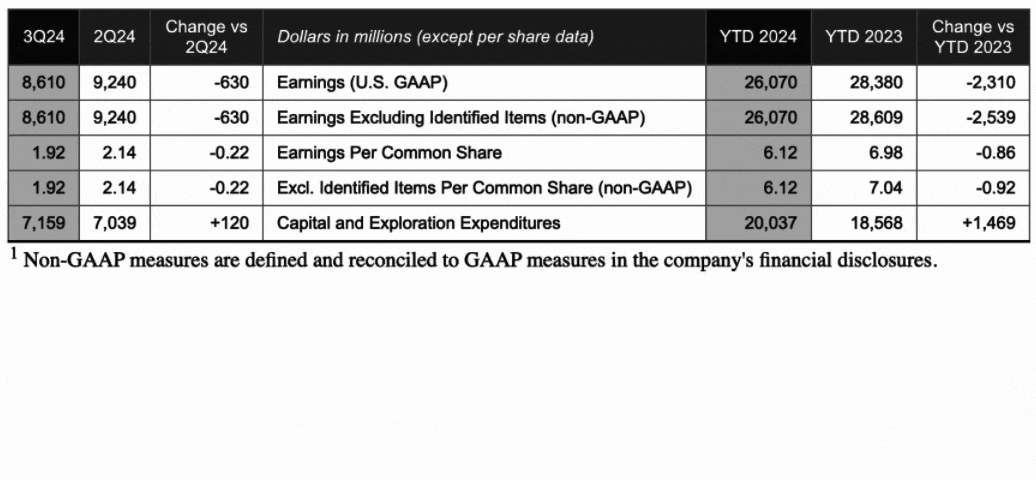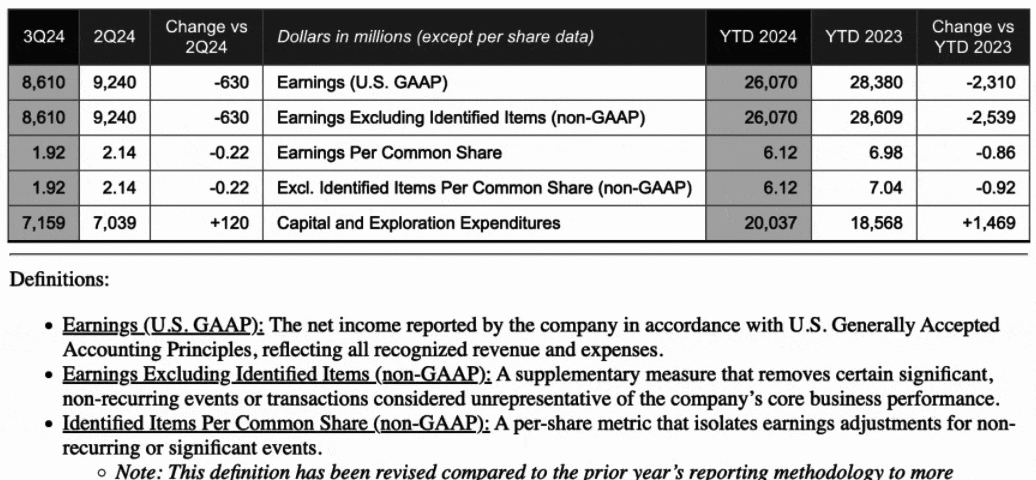
Example below of the hierarchical content generation. The table element will be generated first, and footnotes, justifications, definitions, etc. will reference the parent table element.
Incorporating Images

Lots of documents have embedded images. This is one of the harder elements to incorporate. So far we’ve kept to logos / branding, which is pretty easy to conditionally render on a page.
We start with a data set of a few thousand companies (pretty much the Russell 2000).
Assign a probability of a Header / Footer containing a logo, and pass the company name reference downstream so that any references in the text align with the imagery. That way, the entire page feels more cohesive, rather than just randomly stamped with a logo.

Synthetic vs Human labeled data
We use a mix of labeled and synthetic data for training. And it’s unlikely the human labeled data element will go away any time soon. We’re always finding uniquely bad documents that we need to account for.
However labeled data for our use case is particularly time consuming to produce. Compared to something like image classification, document ⇒ Markdown takes way more time and nuance.
We also have to account for:
Redundant verification. Manual labeling is very error prone. People just aren’t particularly well suited for retyping entire documents by hand.
Data ownership. We’re limited to representative documents that are public domain. And public facing documents often differ significantly in layout from internal documents.
(manually annotating docs to pass time on a flight)

Roadmap
Until we hit 100% on OCR + extraction accuracy, this is going to be a continuous work in progress. And on that note, we are actively hiring for engineers who want to really dig in on document extraction. If you’re interested, check out our available roles, or drop me a line tyler@getomni.ai
OCR Benchmark
We recently launched our OCR benchmark! As part of this, we’ve published an open-source validation dataset consisting of:
Document images
Markdown
JSON Schema
Validated JSON response
As mentioned earlier, our main goal was LLM-based document extraction. To benchmark this, we validated the following workflows:
Image ⇒ Text ⇒ Extraction
In this flow, we ran OCR on a document and passed the resulting text to an LLM along with the JSON schema for extraction. We only evaluated providers on their OCR accuracy, using GPT-4o structured output for the extraction.
Image ⇒ Extraction
For multimodal LLM providers, we will run a separate test of direct extraction without the OCR step (GPT 4o & Anthropic PDF).
We launched the benchmark with the following providers, and now that the test runner is live, it’s easy to add more:
OmniAI
Gemini 2.0 Flash
Azure
Llama 4 Maverick
GPT-4o
Qwen 2.5 VL 72b
AWS Textract
Mistral OCR
Claude Sonnet 3.5
Google Document AI
GPT-4o Mini
Llama 3.2 90b
Unstructured
Gemma-3 27b
Handwriting
This one is pretty straight forward technically. Just need to spend the time exploring all the handwritten fonts out there.
Classic example being the forms you fill out at a doctors office. Typically very dense tables with a variety of input fields, checkboxes, and “circle which one applies”. The hardest part we’ve found so far is keeping text variable while also having it conform to the bounding boxes (calling this the Happy Birthday problem).

(from calligrapher.ai)
Expand representation
You may have noticed from that many of our examples have some industry weighting to them. As a company we’re mostly active in financial and insurance workflows, so our focus is definitely skewed to training data that helps on that front.
The end goal is globally representative document generation. We should have the ability to generate an autobody receipt, income statement, and Vietnamese chemistry textbook all with the same level of fidelity.
Better multipage document generation
Right now we are making one page at a time. For the Image ⇒ Markdown conversion, that’s really all that’s needed. But to expand on multi-image ⇒ JSON training, we’ll need to work on generating longer form content.