4 min read
Apr 6, 2025
The best open source OCR models
For several months, we’ve been evaluating how well vision models handle OCR. Our initial benchmark focused on the closed-source models (GPT, Gemini, and Claude) and their comparisons to traditional OCR providers (AWS, Azure, GCP, etc.).
However this week has been particularly exciting for open source LLMs. In the last few days we got:
And a couple weeks ago we got the new mistral-ocr model. It seemed like a good time to put together a separate OCR benchmark post focusing specifically on the open source vision models.
This new benchmark run includes:
Qwen 2.5 VL 72b
Qwen 2.5 VL 32b
Gemma-3 27b
Mistral-ocr
Llama 3.2 90b
Llama 3.2 11b
Llama 4 Maverick
Llama 4 Scout
Note that DeepSeek-v3 and Llama 3.3 do not yet have native vision support, so they could not be included.
Additionally, while there are tons of other open source OCR providers (Paddle OCR, Docling, Unstructured, etc.), this particular evaluation focuses on open source VLMs only. A follow-up benchmark will revisit traditional OCR models.
As with our main OCR Benchmark, the dataset and methodologies here are entirely open-source. You can review (and reproduce) the evaluation yourself via our benchmark repository on Github and you can view all raw data in our Hugging Face repository.
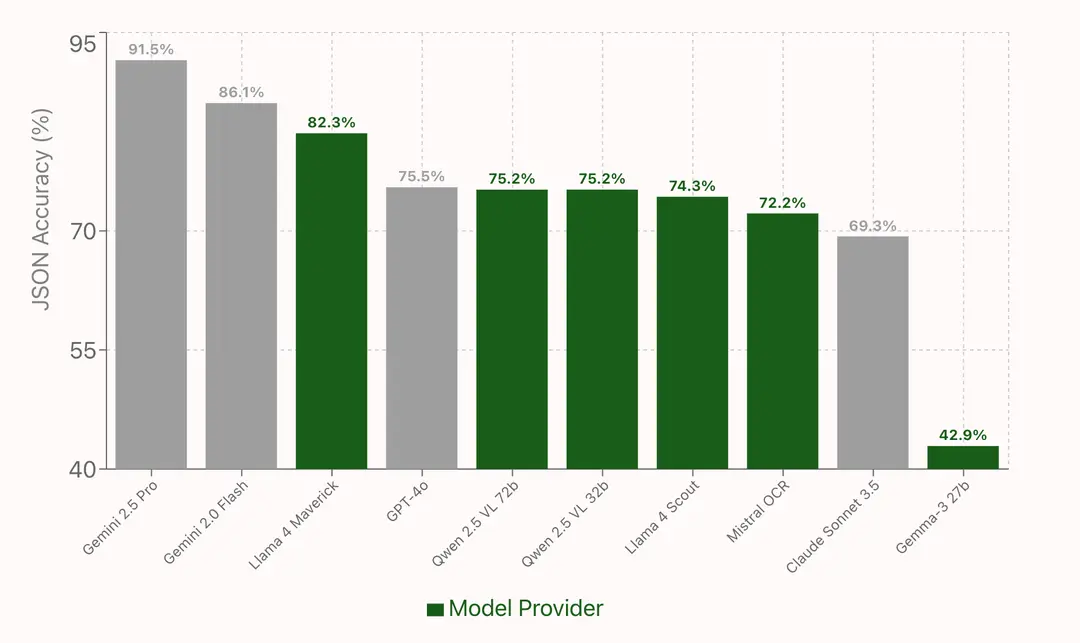
Results at a Glance
After evaluating 1,000 documents for JSON extraction accuracy, cost, and latency, here are the major takeaways among the open-source models:
Qwen 2.5 VL (72B and 32B) are by far the most impressive. Both landed right around 75% accuracy (equivalent to GPT-4o’s performance).
It’s especially noteworthy that both Qwen models edged out mistral-ocr (72.2%), which is specifically trained for OCR.
Gemma-3 (27B) came in at 42.9%, which is particularly surprising given that it's architecture is largely similar to Gemini 2.0 which topped the accuracy chart.
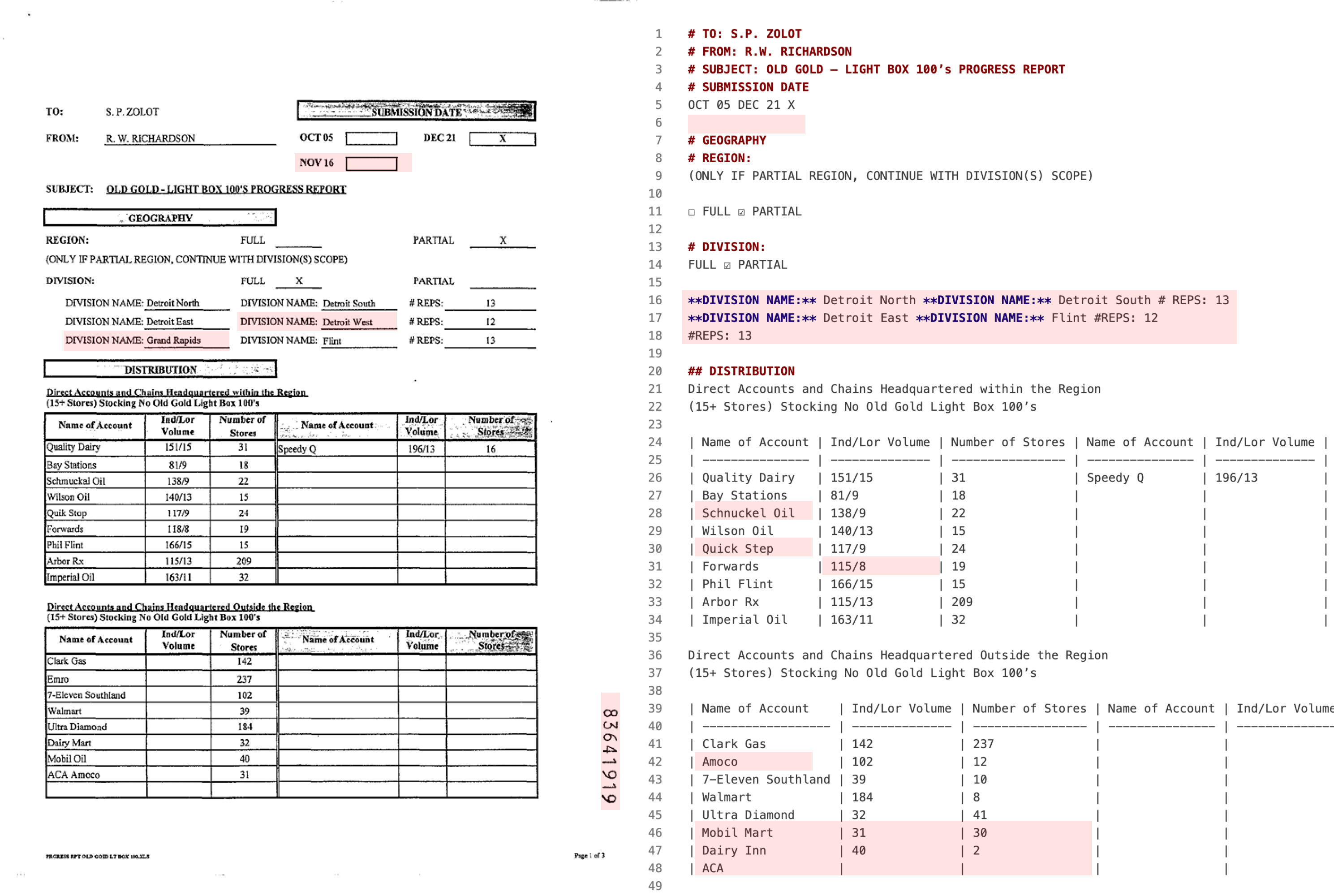
We spent some extra time verifying Gemma-3’s performance because it came in significantly below our expectations. We didn’t observe any single, standout failure mode.
Instead, the errors reflected typical VLM challenges, including hallucinations, omitted values, and swapped words. Below is an example output that appears correctly formatted at first glance, but closer inspection reveals numerous inaccuracies and missing data.
Methodology
For a more details on methodology and scoring check out the original benchmark report: https://getomni.ai/ocr-benchmark
The primary goal is to evaluate JSON extraction from documents. To evaluate this, the Omni benchmark runs Document ⇒ OCR ⇒ Extraction. Measuring how well a model can OCR a page, and return that content in a format that an LLM can parse.
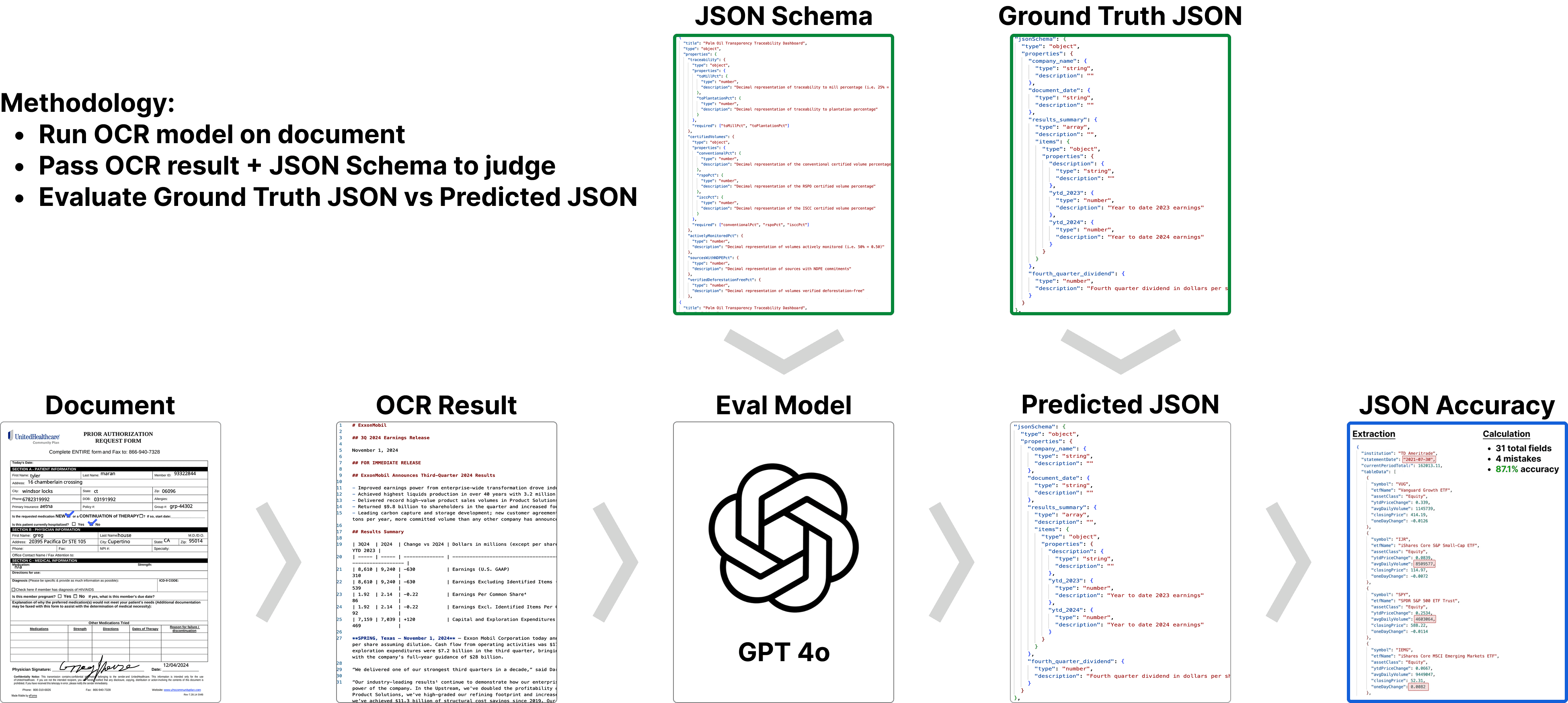
We are using GPT-4o as a judge. Passing in the OCR result + JSON schema using the structured extraction mode. We compare that to the ground truth JSON values to determine accuracy. Several LLMs with structured output were evaluated as judge (including GPT-4o, Claude 3.5 Sonnet, and Gemini 2.0 Flash). GPT 4o most consistently conformed to the JSON schema.
A ground truth accuracy is calculated by passing in the 100% correct text to GPT 4o along with the corresponding JSON Schema. There's always some variability with GPT even given the perfect text input, and we typically see 99% (+/-1%) accuracy on the ground truth.
Notes on Running the Benchmark
Getting up and running with the OS models was a bit more challenging than the hosted APIs from traditional providers. Here’s a quick overview of the infrastructure challenges and solutions we encountered:
Using hosted models
Openrouter by far provides the best early access to models like Gemma-3 and Qwen-2.5-VL-32B but has stricter rate limits on some of the newer models (~200 requests/day).
Hilariously Google AI Studio, while having Gemma-3 support, does not recognize Gemma as a vision model. Compared to Openrouter which had the model and correctly configured image support.
Together.ai has really scalable inference but typically lags on supporting the newest models. But for models like Llama 3.2 this was easy to connect.
Self-Hosting Complexities
You can of course host the models via Hugging Face Inference Endpoint, Friendli, or AWS SageMaker. However it was a bit of a pain to set up for each provider, so we opted for the hosted versions.
Our Final Setup
Gemma-3 was accessed through Openrouter.ai.
Qwen 2.5 VL was eventually run through Dashscope (Alibaba Cloud Model Studio). Initial testing was done on Openrouter, but we needed a bigger rate limit to run the full benchmark.
Llama 3.2 inference was hosted by Together.ai.
These hosting setups may change as new providers add vision model support or increase rate limits. But these are the endpoints live in the benchmark runner today.
Resources:
Omni Benchmark Repository for full reproduction
Hugging Face Repository for raw data and JSON schemas
Questions or suggestions? Feel free to open an issue on GitHub or reach out on our community channels.