
"Hallucination" is part of thought
> "GPT would be great if it didn't hallucinate all the time"
> "How do we make sure GPT doesn't hallucinate the wrong answer"
> "OpenAI need to fix the hallucination problem"
Hallucinating, the popular term for GPT confidently spewing incorrect data. It's often cited as the main reason not to use an LLM in a production environment: "we don't know if it will hallucinate wrong information". The prevailing sentiment seems to be that the "hallucination problem" will simply get patched out in an new version.
While I sympathize with the desire, this represents a failure of understanding of how LLMs operate. The word "hallucination" is likely the culprit. It's easily framed as an 'error in thinking' that needs to be resolved. But in GPT's case, "hallucination" is part of thought.
People want the "good hallucination".
- "Explain the iPhone like Abraham Lincoln"
- "Write me some code to generate a 3d model of an Owl" (pictured above)
When GPT answers these questions, it's not looking up an actual Lincoln quote about iPhones. Solving a new problem requires stringing together data in a novel fashion. Eliminating "hallucination" eliminates the magic that separates GPT from a Google search.
More data helps, but can only get you so far
The easist option would be to keep feeding GPT more data. Over time it should fix the problem itself right? Yes and no. While GPT 3.5 to GPT4 has some pretty obvious improvements, it's unlikely we'll see another huge jump from training data alone.
This is part of the reason OpenAi isn't full steam ahead on GPT-5. Additional training data has diminishing marginal returns. Simply piling more data on top of the same model will less and less noticable effects.
GPT 3.5 with a trick question
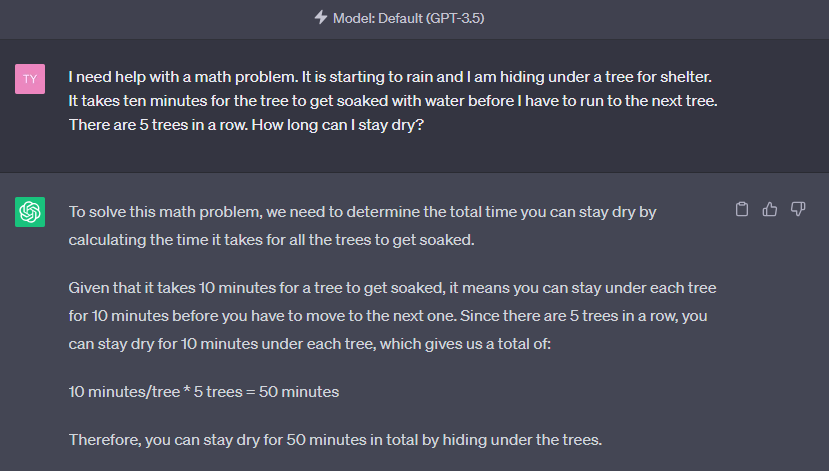
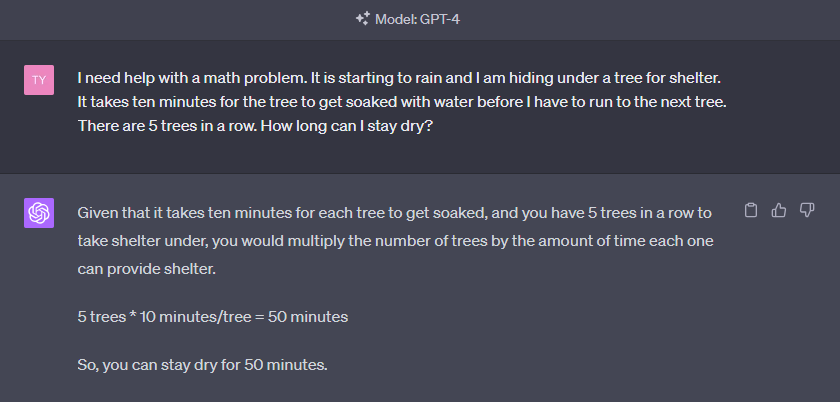
GPT4 failing the same question
Fact checking the AI
Hallucination is easy to solve if you *know* the right answer. Just take the GPT response and douple check it against the proper answer. But then, if you know the right answer to the question, why not pass it back directly rather than asking GPT.
But there are some cases where this works. LLMs fail pretty regularly when presented with null data (some examples).
Here's we have a user requesting a search and the api failing.
User: search for houses near me Api Response: [api errors] LLM Response: Sure thing! I found: - 123 Whitehouse Street - 221B Baker Street
In this scenario, we know the data returned by the API (null) and we know the LLM response. So we can run another request to the LLM with a fact-check query:
A user asked the following question:
{question}
A tool provided the following data:
{api_response}
The AI responded with:
{api_response}
Does the above API response correctly answer user question using the data provided? Return a one word reply that is either YES, NO, UNCLEAR. If the answer is 'YES', pass along the first result. Otherwise retry.
This method is relatively effective for fact checking single responses. A frequent source of hallucination is overfitting to conversation history. By passing a context free request a lot of that surperflorus information is removed.
However it still relies on the underlying LLM to answer correctly. A "who will guard the guards" scenario.
Learning to live with Hallucinations
The technology is new and I expect that LLM use cases will change over time. GPT is not the sanitized customer chat bot that many companies desire. No amount of prompt engineering will prevent GPT from making up a fact, or operating outside it's boundries.
It is still highly useful for these cases, but as a classifying tool rather than a drirect response. (i.e. 'classify the follwing question into one of [x,y,z] categories`).
But when some amount of creativity and problem solving are necessary , GPT's ability to imagine and construct unique responses can be invaluable. It can generate unexpected solutions and innovative ideas, leading to novel perspectives and insights that wouldn't be achieved with mere factual regurgitation.
The key to leveraging this technology is to acknowledge its strengths and weaknesses, to understand when to rely on its 'creativity' and when to validate its 'facts.'
Do you need a database or a mathematical equation solved accurately every single time? Then, it might be best to resort to a more deterministic system. But when faced with abstract queries or problems that require an inventive approach, GPT truly shines.