
Enriching data, without moving it
I want to do a quick dive into a new Omni feature that saves an enormous amount of headache for data engineers. This is our in warehouse data transformation.
At the click of a button, Omni manages the full lifecycle of:
- Reading realtime data from your warehouse
- Hosting and running an LLM to transform data
- Writing the enriched data back to the orginal warehouse
If you've been in the trenches of data engineering and pipeline building, you've probably built this exact flow a dozen times by now. And it only gets worse as more and more tools are added to the "Modern Data Stack". Eventually everyone ends up with a rube goldberg of Airflow, dbt, Fivetran and a handful of Lambda's to do the actual transformation work.
On top of the orchestration headache, each new platform you add to the flow increases infosec and data governance concerns.
Even simple enrichment tasks can become a data orchestration nightmare
If you've ever been tasked with doing some form of data enrichment or cleanup, it usually involves quite a few steps. Lets go through a basic example. Imagine you're using a tool like Fivetran to pipe data from Zendesk over to Snowflake, and you want to run sentiment classification on each issue. The steps would probably look like:
- Set up and deploy a sentiment model. You might pick a model from Huggingface, or use one of the AWS/Azure text analytics services.
- Create a Lambda to call the sentiment model with your data.
- Create a new column or table for your output data.
- Set up a listener on your warehouse for any new data. You would likely setup Snowflake Streams, or SnowPipe, to continuously pick up on new rows.
- Run a batch job to backfill of all your existing data.
This setup isn't terrible if you're doing a single data transformation, but it quickly balloons if your requirements become more complex.
If you're working with an unstructured data source like support tickets you'll need to do more than a sentiment model. It's likely you'd want to run categorization, topic identification, find common complaints, etc. And if you need to test out 2-3 different variants of each model to evaluate results, it quickly becomes a huge engineering burden.
Unstructured data requires a lot of experimentation
LLMs have opened up a ton of new capabilities for data teams. A lot of previously inaccessible data is now much easier to access. But working with brand new data sets will always requires iteration and experimentation. Things like:
- Which models give the best performance / cost ratio on your specific data
- What set of categories are most appropriate for the dataset.
- How do we fine tune prompts to improve accuracy
Today each iteration can take days of engineering time. It's not easy to spin up a dozen LLMs to do these kind of test runs!
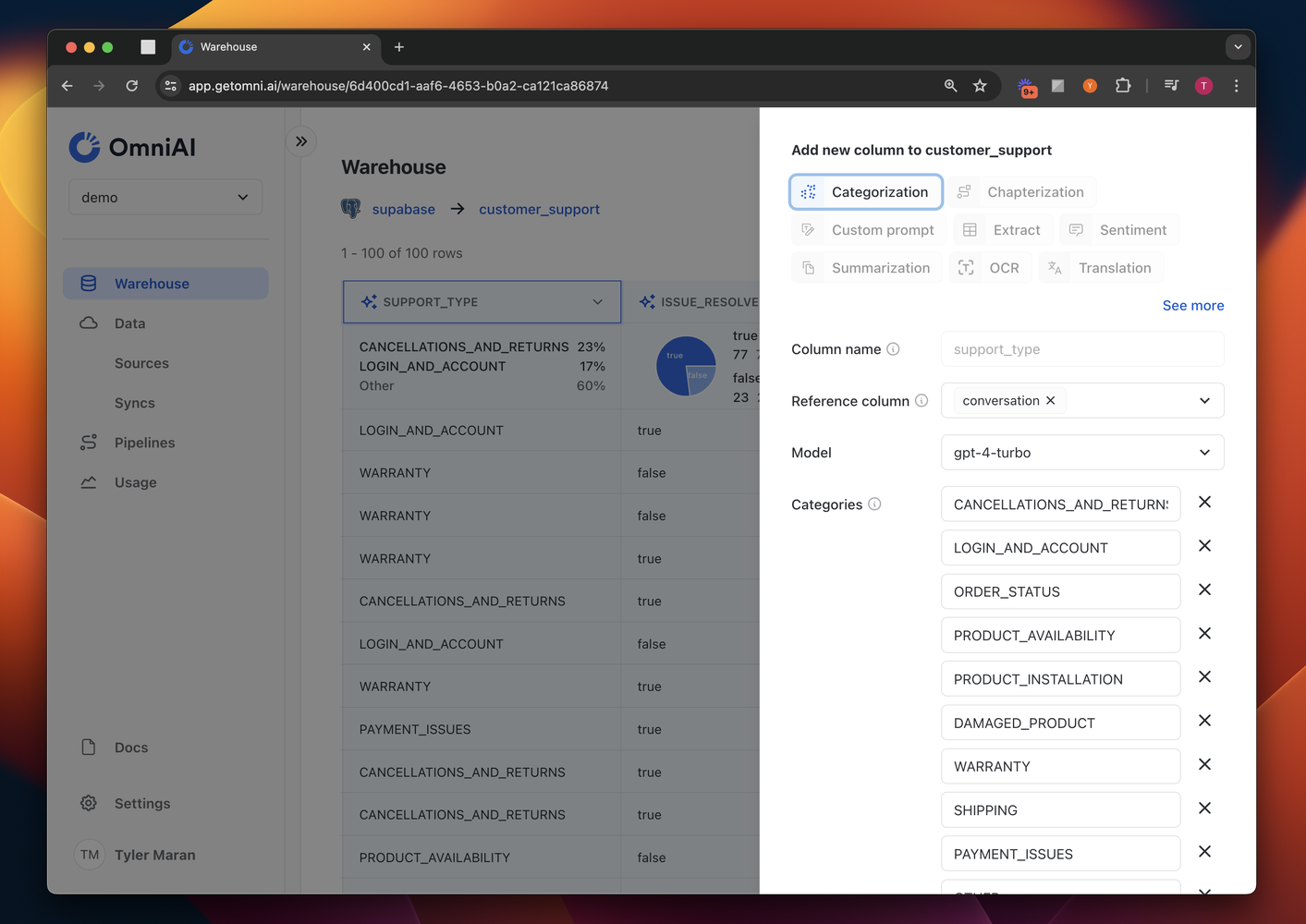
Focus on transformation, not the orchestration
Our focus is on empowering you to focus on the transformative aspects of data engineering, rather than getting bogged down by the orchestration. With Omni’s In Warehouse transformations, you're equipped to implement powerful LLM capabilities directly within your existing data environment.
This means you can run complex data transformations like sentiment analysis, categorization, and topic identification without the hassle of managing multiple integrations or worrying about data governance issues. And instead of being stuck in the setup phase, your team can move off orchestration, and onto building something useful with that data!